Unity : ComputeShader のシンプルなサンプル(1)

Unity でコンピュートシェーダ(ComputeShader)を使う方法について、シンプルに解説します。 ここでは適当な計算をコンピュートシェーダ(GPU) に任せて、その結果を配列として取得する方法について扱います。 サンプルには次のような操作が含まれます。
- コンピュートシェーダを使って複数のデータを処理し、その結果を取得する。
- 1 つのコンピュートシェーダに複数の機能を実装し、使い分ける。
- コンピュートシェーダ (GPU) にスクリプト側 (CPU) から値を渡す。
サンプルには先に目を通しておくことを推奨します。
- Unity_SimpleComputeShader
- このページで解説するのは SampleScene_Array と関連するリソースです。
- テクスチャを操作するサンプルは (2) で解説します。
カーネル、スレッド、グループの概念
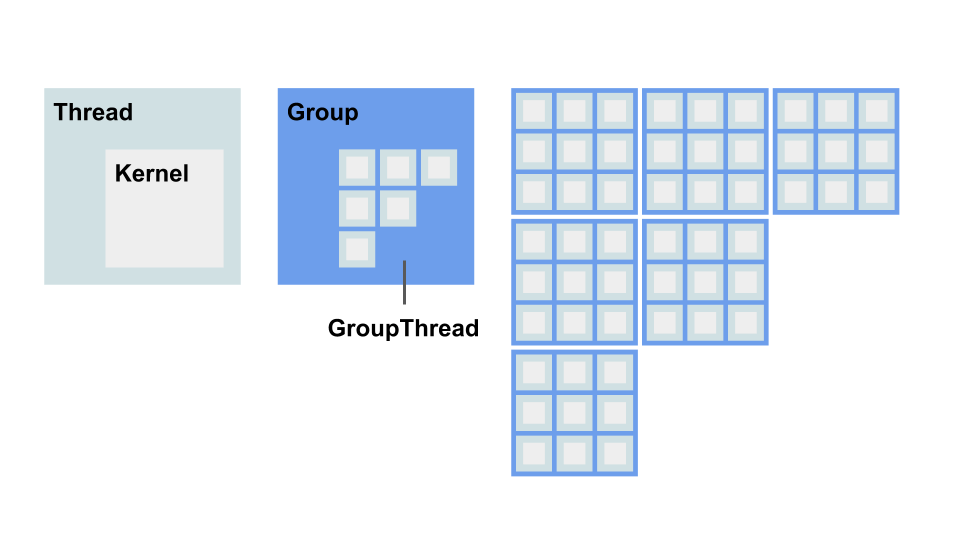
イメージ図上ではスレッドとグループが 2 次元ですが、実際には 3 次元です。
具体的な実装の前に、コンピュートシェーダで取り扱われる、 カーネル、スレッド、グループの概念を説明しておく必要があります。
正確な定義はさておき、カーネルとは、GPU で実行される1つの処理を指し、コード上では 1 つの関数として扱われます。 関数やメソッドと呼べば良いような気がしますが、多くの資料でカーネルとされる便宜上、カーネルで覚えておくべきでしょう。
スレッドとは、カーネルを実行する単位です。 コンピュートシェーダではカーネルを複数のスレッドで並行して同時に実行することができます。 スレッドは (x, y, z) の3次元で指定しす。
例えば、(4, 1, 1) なら 4 * 1 * 1 = 4 つのスレッドが同時に実行されます。 (2, 2, 1) なら、2 * 2 * 1 = 4 つのスレッドが同時に実行されます。 同じ 4 つのスレッドが実行されますが、状況に応じて、後者のような 2 次元でスレッドを指定する方が効率が良いことがあります。 これについては後に続く資料で解説します。ひとまずスレッド数は 3 次元で指定されるという認識が必要です。
最後にグループとは、スレッドを実行する単位です。また、あるグループが実行するスレッドは、グループスレッドと呼ばれます。
例えば、あるグループが単位当たり、(4, 1, 1) スレッドを持つとします。 このグループが 2 つあるとき、それぞれのグループが、(4, 1, 1) のスレッドを持ちます。
グループもスレッドと同様に 3 次元で指定されます。例えば、(2, 1, 1) グループが、(4, 4, 1) スレッドで実行されるカーネルを実行するとき、 グループ数は 2 * 1 * 1 = 2 です。この 2 つのグループは、それぞれ 4 * 4 * 1 = 16 スレッドを持つことになります。 したがって、合計スレッド数は、2 * 16 = 32 となります。
ここでは Unity 上でコンピュートシェーダを実装する方法について解説していますが、 概ね OpenCL や CUDA などの GPGPU プログラミングでも同じような考え方が通用するような気はします。
コンピュートシェーダの概要
非常に短いので、コンピュートシェーダは先に一通り目を通して頂くのが良いと思います。
#pragma kernel KernelFunction_A
#pragma kernel KernelFunction_B
RWStructuredBuffer<int> intBuffer;
float floatValue;
[numthreads(4, 1, 1)]
void KernelFunction_A(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] = groupThreadID.x * floatValue;
}
[numthreads(4, 1, 1)]
void KernelFunction_B(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] += 1;
}カーネル(kernel) の定義
先に解説した通り、正確な定義はさておき、カーネルは GPU で実行される1つの処理を指し、コード上では1つの関数として扱われます。
カーネルは1つのコンピュトシェーダに複数実装することができます。
この例では、カーネルは KernelFunction_A ないし KernelFunction_B 関数がカーネルに該当します。
カーネルとして扱う関数は #pragma kernel を使って定義します。
これによってカーネルとそれ以外の関数と識別します。
カーネルの順序
コンピュートシェーダに定義された複数のカーネルのうち、任意の 1 つを識別するために、固有のインデックス(順序データ)がカーネルに与えられます。
インデックスは #pragma kernel で定義された順に、上から 0, 1 … と与えられるようです。
カーネルの実装
この項目で解説するカーネルは次のようになっています。
RWStructuredBuffer<int> intBuffer;
int intValue;
[numthreads(4, 1, 1)]
void KernelFunction_A(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] = groupThreadID.x * intValue;
}バッファや変数の用意
まずコンピュートシェーダで実行した結果を保存するバッファ領域を作っておきます。
この例では int 型の配列を結果として保存するとします。
サンプルの変数 RWStructuredBuffer<int> intBuffer がこれに該当します。
また必要なら スクリプト (CPU) 側からデータを与えたい場合があるでしょう。
この例では変数 intValue に、スクリプトから値を渡します。
RWStructuredBuffer<int> intBuffer;
int intValue;numthreads による実行スレッド数の指定
numthreads 属性 (Attribute) は、このカーネルを実行するスレッドの数を指定します。
スレッド数の指定は、(x, y, z) で指定し、例えば (4, 1, 1) なら、 4 * 1 * 1 = 4 スレッドでカーネルを実行します。
(2, 2, 1) なら 2 * 2 * 1 = 4 スレッドでカーネルを実行します。
共に 4 スレッドで実行されますが、この違いや使い分けについては次の資料で説明します。
カーネルの引数
カーネルに設定できる引数には制限があります。
この例では groupID : SV_GroupID と groupThreadID : SV_GroupThreadID を設定しています。
引数: に続く値をセマンティクスと呼びますが、これは引数がどのような値であるかを示すための物であり、
他の名前に変更することができません。引数名(変数名)は自由に変更することができます。
SV_GroupID は、カーネル(を実行するスレッド)が、どのグループで実行されているかを (x, y, z) で示します。
SV_GroupThreadID は、カーネルを実行するスレッドが、グループ内の何番目のスレッドであるかを (x, y, z) で示します。
例えば (4, 4, 1) のグループで、(2, 2, 1) のスレッドを実行するとき、
SV_GroupID は (0 ~ 3, 0 ~ 3, 0) の値を返し、SV_GroupThreadID は (0 ~ 1, 0 ~ 1, 0) の値を返します。
ほかにも SV_~ から始まるセマンティクスがあり、利用することができますが、ここでは解説を割愛します。
一通りコンピュートシェーダの動きが分かった後に目を通すほうが良いと思います。
カーネルの処理内容
上記の説明を確認した上で、具体的な処理内容を確認します。
用意したバッファに、順にスレッド番号を代入していくような処理を行っています。
groupThreadID は、あるグループで実行されるスレッド番号が与えられます。
このカーネルは (4, 1, 1) で実行されますから、groupThreadID は (0 ~ 3, 0, 0) が与えられます。
[numthreads(4, 1, 1)]
void KernelFunction_A(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] = groupThreadID.x * intValue;
}今回のサンプルはこのスレッドを、(1, 1, 1) のグループで実行します(後に説明するスクリプトから)。 すなわちグループを 1 つだけ実行し、そのグループには、4 * 1 * 1 のスレッドが含まれます。
結果として、groupThreadID.x には 0 ~ 3 の値が与えられることを確認してください。
またこの例では groupID を利用していませんが、スレッドと同様に、3次元で指定されるグループ数が与えられます。
代入してみるなどして、コンピュートシェーダの動きを確認するために使ってみてください。
スクリプトからコンピュートシェーダを実行する
実行の準備
実装した ComputeShader をスクリプトから実行します。 実行に当たってスクリプト側で必要になるものは概ね次の通りです。 下記のコードの変数と合わせて参照できるようにしています。
- コンピュートシェーダへの参照 |
comuteShader - 実行したいカーネルのインデックス(順序) |
kernelIndex_KernelFunction_A(B) - コンピュートシェーダを実行した結果を保存するバッファ領域。|
intComputeBuffer
public ComputeShader computeShader;
int kernelIndex_KernelFunction_A;
int kernelIndex_KernelFunction_B;
ComputeBuffer intComputeBuffer;
void Start()
{
this.kernelIndex_KernelFunction_A
= this.computeShader.FindKernel("KernelFunction_A");
this.kernelIndex_KernelFunction_B
= this.computeShader.FindKernel("KernelFunction_B");
this.intComputeBuffer = new ComputeBuffer(4, sizeof(int));
this.computeShader.SetBuffer
(this.kernelIndex_KernelFunction_A,
"intBuffer", this.intComputeBuffer);
this.computeShader.SetInt("intValue", 1);
…カーネルインデックスの取得
あるカーネルを実行するためには、そのカーネルを指定するためのインデックス情報が必要です。
this.kernelIndex_KernelFunction_A
= this.computeShader.FindKernel("KernelFunction_A");
this.kernelIndex_KernelFunction_B
= this.computeShader.FindKernel("KernelFunction_B");実行したいカーネルのインデックスは定数で指定しても良いですが、
Unity では FindKernel("カーネル名") で取得することができます。
現実的にはこの方法で取得した方が良いでしょう。
バッファの生成
コンピュートシェーダの結果を保存するためのバッファ領域は、実行前にあらかじめ確保しておく必要があります。 動的に用意することはできません(方法はあるのかもしれませんが)。
this.intComputeBuffer = new ComputeBuffer(4, sizeof(int));
this.computeShader.SetBuffer
(this.kernelIndex_KernelFunction_A, "intBuffer", this.intComputeBuffer);ComputeBuffer を、保存する領域のサイズ、保存するデータの単位当たりのサイズを指定して初期化します。
次いで、ComputeShader に実装されたどのカーネルが実行するときに、どのバッファを使うのかを指定します。
この例では、KernelFunction_A が実行されるときに参照される、
(コンピュートシェーダ内にある)intBuffer なるバッファ領域は、
intComputeBuffer で指定する領域だけ確保する、となっています。
intComputeBuffer は int 型のサイズ 4 つ分で確保されています。
4 つ分である理由は後の解説を読み進めると分かります。
スクリプト (CPU) 側から値を渡す
this.computeShader.SetInt("intValue", 1);処理したい内容によってはスクリプト (CPU) 側からコンピュートシェーダ (GPU) 側に値を渡し、
参照したい場合があると思います。ほとんどの型の値は ComputeShader.Set~ を使って、
コンピュートシェーダ内にある変数に設定することができます。
このとき引数に設定する引数の名称は、コンピュートシェーダに定義された変数名と一致する必要があります。
この例では intValue に 1 を渡しています。
コンピュートシェーダ(カーネル)の実行
コンピュートシェーダに実装されたカーネルは、Dispatch メソッドで実行します。
指定したインデックスのカーネルを、指定したグループ数で実行します。
グループ数は X * Y * Z で指定します。この例では 1 * 1 * 1 = 1 グループです。
this.computeShader.Dispatch(this.kernelIndex_KernelFunction_A, 1, 1, 1);
int[] result = new int[4];
this.intComputeBuffer.GetData(result);
for (int i = 0; i < 4; i++)
{
Debug.Log(result[i]);
}コンピュートシェーダの実行結果は、必要なら、ComputeBuffer.GetData で取得することができます。
バッファ領域と同じ型とサイズの変数に、コンピュートシェーダで実行した結果を保存します。
実行結果の確認(A)
この例では次のカーネルを 1 * 1 * 1 = 1グループで実行しています。
スレッドは、4 * 1 * 1 = 4 スレッドです。
また intValue にはスクリプトから 1 を与えています。
[numthreads(4, 1, 1)]
void KernelFunction_A(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] = groupThreadID.x * intValue;
}groupThreadID(SV_GroupThreadID) は、今このカーネルが、グループ内の何番目のスレッドで実行されているかを示す値が入るので、
この例では (0 ~ 3, 0, 0) が入ります。したがって、groupThreadID.x は 0 ~ 3 です。
つまり、intBuffer[0] = 0 ~ intBuffer[3] = 3 までが並列して実行されることになります。
先に intBuffer を int 型 4 つ分のサイズで初期化したのはこのためです。
コンピュートシェーダでは、必要になるバッファ領域を把握し、あらかじめ固定値として用意する必要があります。
この例では、デバッグ出力していますが、0 ~ 3 が順に出力されたことを確認してください。
異なるカーネルを実行する
1 つのコンピュートシェーダに実装した異なるカーネルを実行するときは、別のカーネルのインデックスを指定します。
この例では、KernelFunction_A を実行した後に KernelFunction_B を実行します。
さらに、KernelFunction_A で利用したバッファ領域を、KernelFunction_B でも使ってみます。
this.computeShader.SetBuffer
(this.kernelIndex_KernelFunction_B, "intBuffer", this.intComputeBuffer);
this.computeShader.Dispatch(this.kernelIndex_KernelFunction_B, 1, 1, 1);
this.intComputeBuffer.GetData(result);
for (int i = 0; i < 4; i++)
{
Debug.Log(result[i]);
}実行結果の確認(B)
KernelFunction_B は次のようなコードを実行します。
このとき、intBuffer は KernelFunction_A で使ったものを引き続き指定している点に注意してください。
RWStructuredBuffer<int> intBuffer;
[numthreads(4, 1, 1)]
void KernelFunction_B(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] += 1;
}この例では、KernelFunction_A によって intBuffer には 0 ~ 3 が順に与えられています。
したがって KernelFunction_B の実行結果は、1 ~ 4 になることを確認します。
バッファの破棄
利用し終えた(コンピュート)バッファは明示的に破棄する必要があります。
this.intComputeBuffer.Release();Unity で利用される C# はマネージドコード、つまり自動で不要なメモリ領域を確認され、 自動でガーベージコレクションが走るタイプの言語(と実装)です。
しかしながらコンピュートシェーダの機能を利用する場合は、 実行結果を保存する領域にガーベージコレクションが走ると困ります(アンマネージドな機能)。 したがって、明示的にメモリ領域を確保し、明示的に開放する必要があります。
解決していない問題
多次元のスレッドまたはグループを指定する意図について、この例では解説していません。 例えば、 (4, 1, 1) スレッドと、(2, 2, 1) スレッドは、どちらも 4 スレッド実行されますが、 この 2 つは使い分ける意味があります。
これについては後に続く資料で解説します。